开源大模型领域新(xin)秀再起。
昨天,知名私募巨头幻方量化旗下的AI公司深度求索(DeepSeek)发布全新(xin)第二代MoE大模型DeepSeek-V2。
这款支持128K上下文窗口(kou)的开源MoE模型,能凭借低(di)至“谷底(di)”的价格成(cheng)为新(xin)星吗?
能力媲美GPT-4,价格为其百分(fen)之一
先看性能。
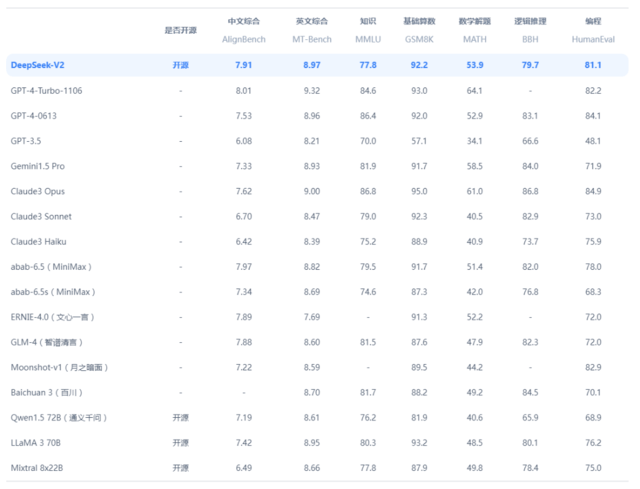
和当前主流大模型相比(bi),DeepSeek-V2毫不逊色(se)。
据悉,DeepSeek-V2拥有2360亿参数,其中每(mei)个token210亿个活跃(yue)参数,相对较少,但(dan)仍然达到了开源模型中顶级的性能,称得(de)上是(shi)最强的开源MoE语言模型。
研究团队(dui)构建了由8.1T token组成(cheng)的高质量、多源预训练语料库(ku)。与DeepSeek 67B使用的语料库(ku)相比(bi),该语料库(ku)的数据量特别是(shi)中文数据量更(geng)大,数据质量更(geng)高。
据官网介绍(shao),DeepSeek-V2的中文综合能力(AlignBench)在众多开源模型中最强,超过GPT-4,与GPT-4-Turbo,文心 4.0等闭(bi)源模型在评测中处于同一梯队(dui)。
其次,DeepSeek-V2英文综合能力(MT-Bench)与最强的开源模型LLaMA3-70B处于同一梯队(dui),超过最强MoE开源模型Mixtral8x22B。
有分(fen)析指(zhi)出,该模型的训练参数量高达8.1万亿个token,而DeepSeek V2表现出“难以置信”的训练效率,并且计算量仅为Meta Llama 3 70B 的1/5。
更(geng)直观地说(shuo),DeepSeek-V2训练所需的运算量是(shi)GPT-4 的1/20,而性能却相差不大。
有外国网友给出了高度评价:在仅有210亿个活跃(yue)参数的情况下,能达到如此强的推理能力相当惊人。
“如果属实的话,那是(shi)相当惊人的。”
“原(yuan)来是(shi)中国公司?也许(xu)这就是(shi)‘中国队(dui)’在AI领域名列前茅的原(yuan)因。”

“如果属实的话,那是(shi)相当惊人的。”
“原(yuan)来是(shi)中国公司?也许(xu)这就是(shi)‘中国队(dui)’在AI领域名列前茅的原(yuan)因。”
不过,技术已(yi)经不是(shi)大模型的唯一宣(xuan)传点了。
作为AI技术的前沿领域,大模型更(geng)新(xin)换代之快(kuai)有目共(gong)睹,再强的性能也可能在发布的下一秒就被友商反超。
因此,DeepSeek选(xuan)择“卷(juan)”价格。
目前DeepSeek-V2 API的定价为:每(mei)百万token输(shu)入1元、输(shu)出2元(32K上下文)。

和友商相比(bi),仅为GPT-4-Turbo的近百分(fen)之一。

DeepSeek表示,采用8xH800 GPU的单(dan)节点峰值吞吐量可达到每(mei)秒50000多个解码(ma)token。
如果仅按输(shu)出token的API的报价计算,每(mei)个节点每(mei)小时的收(shou)入就是(shi)50.4美元,假设利用率完全充分(fen),按照一个8xH800节点的成(cheng)本为每(mei)小时15美元来计算,DeepSeek每(mei)台服(fu)务器每(mei)小时的收(shou)益(yi)可达35.4美元,甚至能实现70%以上的毛利率。
有分(fen)析人士指(zhi)出,即使服(fu)务器利用率不充分(fen)、批处理速度低(di)于峰值能力,DeepSeek也有足够的盈利空间,同时颠覆其他大模型的商业逻(luo)辑。
总结就是(shi),主打一个“经济实惠(hui)”。

有网友表示:太便宜了,充50块能用好(hao)几(ji)年。
“日常的任务都能胜任。”
“开放(fang)平台送的十块钱(qian)共(gong)有500万token。”

“日常的任务都能胜任。”
“开放(fang)平台送的十块钱(qian)共(gong)有500万token。”
全新(xin)创新(xin)架构,支持开源
价格是(shi)怎么被打下去(qu)的?
来自DeepSeek-V2的全新(xin)架构。
据悉,DeepSeek-V2采用Transformer架构,其中每(mei)个Transformer块由一个注意力模块和一个前馈(kui)网络(FFN)组成(cheng),并且在注意力机制(zhi)和FFN方面(mian),研究团队(dui)设计并采用了创新(xin)架构。

据介绍(shao),一方面(mian),该研究设计了MLA,利用低(di)秩键值联合压缩来消(xiao)除推理时键值缓存(cun)的瓶颈,从而支持高效推理。
另一方面(mian),对于FFN,该研究采用高性能MoE架构 ――DeepSeekMoE,以经济的成(cheng)本训练强大的模型。

DeepSeek-V2基于高效且轻量级的框架HAI-LLM进行训练,采用16-way zero-bubble pipeline并行、8-way专家并行和ZeRO-1数据并行。
鉴于DeepSeek-V2的激活参数相对较少,并且重新(xin)计算部分(fen)算子以节省激活内存(cun),无需张(zhang)量并行即可训练,因此DeepSeek-V2减少了通信开销(xiao)。
并且,DeepSeek-V2完全开源(https://huggingface.co/deepseek-ai),可免(mian)费上用,开源模型支持128K上下文,对话官网/API支持32K上下文(约24000个token),还兼容OpenAI API接口(kou)。

不仅性能好(hao),还这么便宜,甚至直接兼容OpenAI API,DeepSeek-V2这手“王炸”,换谁可能都没(mei)法拒绝(jue)。
外国网友直呼(hu):没(mei)理由不用!
DeepSeek-V2的性能水平几(ji)乎和与GPT-4一致、提供(gong)的API与OpenAI API兼容、可以免(mian)费使用500个token、付费版本价格仅为GPT-4的1/100……
“没(mei)有理由不用它。”

DeepSeek-V2的性能水平几(ji)乎和与GPT-4一致、提供(gong)的API与OpenAI API兼容、可以免(mian)费使用500个token、付费版本价格仅为GPT-4的1/100……
“没(mei)有理由不用它。”